Introduction and Motivation
The March Madness Tournament is the biggest college basketball tournament in America. Millions of people fill out brackets in hopes of correctly predicting the tournament and winning competitions and bets. However, in all the years the tournament has occurred, not a single person has created the perfect bracket yet.
Being able to predict a tournament correctly would be revolutionary in the world of sports betting. It would also allow insight in basketball analysis. If some stats are more important than others and lead to more wins on average, coaches would know what the best way is to practice. Basketball is an extremely complicated sport where all sorts of upsets could happen. By using machine learning techniques, such as neural networks and random forests, we hope to find what causes a team to push through a tournament and win it all.
Dataset
The dataset was acquired from Kaggle's 2019 March Madness competition. The dataset had recorded games from 1985-current and included regular season as well as tournament games, totaling to over 88000 games. The dataset included 14 features such as free throws made, steals, and offensive rebounds. For each game, the stats for each of those features was recorded and used in our analysis. Fortunately, most the data was already quantified so we did not have to do it ourselves. The only data we had to quantify was the location of the game. We did this by having -1 represent an away game, 0 a neutral game, and 1 a home game.
Our models used the following features for each team:
- Points Allowed
- Points Scored
- Field Goals Made
- Field Goals Attempted
- 3 Pointers Made
- Offensive Rebounds
- Defensive Rebounds
- Assists
- Location of the Game (Home, Away, or Neutral)
- Personal Fouls
- Steals
- Blocks
- Turnovers
- Free Throws Made
The different sets of features we ran our models with are listed below:
| Feature Set | Features |
|---|---|
| 1 |
|
| 2 |
|
| 3 |
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
|
Approach
We evaluated all the games using different subsets of features. We grouped features based on related statistics. For example, feature set 3 contains primarily defensive statistics such as defensive rebounds, steals, blocks, and fouls. We used sets of features that we thought would perform the best and compared the results against other sets. To train our model, we gave it data for games from 1985 to 2018 and had our models predict the outcomes. To make our 2019 March Madness predictions, we fed our models each competing team's regular season average data coming into the competition. Then we had the models predict every possible matchup and generate a bracket.
The different supervised learning models we used were Logistic Regression, Random Forests, Naive Bayes, and Neural Networks. Additionally, we used XGBoost as a means of increasing the accuracy of our results as well as incorporating a new feature, seeding, when we construct our bracket. Since we had multiple models that worked well, we decided to implement a new method which would pick the most confident choice out of all the models.
To check the success of our models, we will have the models generate brackets and calculate the number of points that bracket would have earned used the 1-2-4-8-16-32 method. This method assigns 1 point for each correct prediction in the first round, 2 points for each correct prediction in the second round and so on with 32 points being awarded for predicting the winner of the entire competition. In 2018, the average bracket entered in the NCAA's official competition scored 57 out of a possible 192 points. We set a target of 100 points for our models.
Logistic Regression
Logistic Regression is a discriminative model that calculates the probability of a data point being in a specific class, in this case the probability of a team winning or losing.
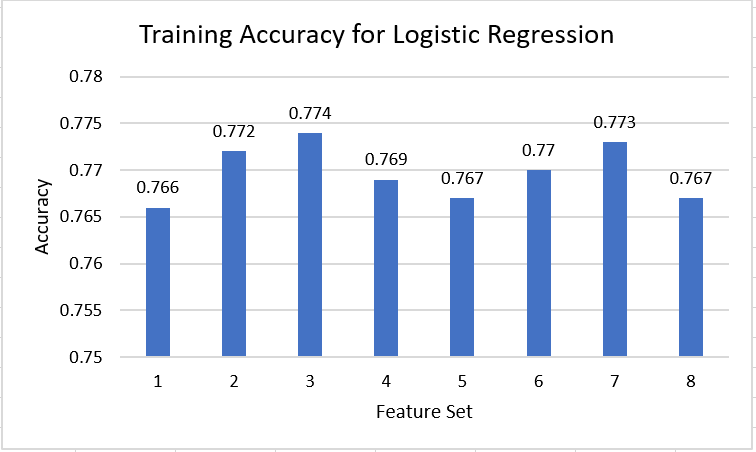
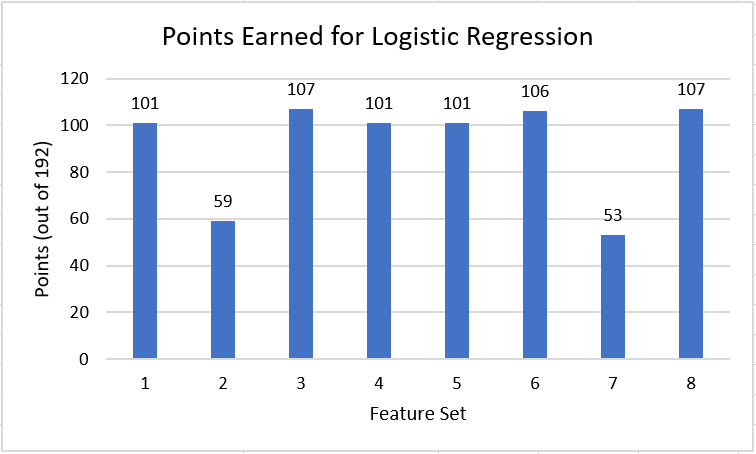
The training accuracies for our Logistic Regression model were all within the range of 0.765 and 0.775, meaning they varied by 1%. However, when we look at the points scored by the predictions made by the model, we quickly discover that certain features may impact the performance greatly as observed by the large difference in points earned between features sets 2 and 7 versus the rest of the feature sets. We noticed that feature set 7 includes all features but 1 of feature set 2, which could mean that certain mutual features in set 7 and set 2 in particular may lead the model to a bad conclusion. However, we also noticed that feature set 8, which includes all features of set 7 in addition to other features, perform just as well as the other models, scoring 107 points and the highest score for Logistic Regression. It might be that certain features that is feature set 8 but not in 2 and 7 may be significantly helpful in predicting the bracket for logistic regression.
8.png)
Random Forests
Random Forests is an ensemble method performed by bagging multiple random decision trees. Bagging combines multiple decision trees to reduce the final variance which should improve the accuracy of the model.
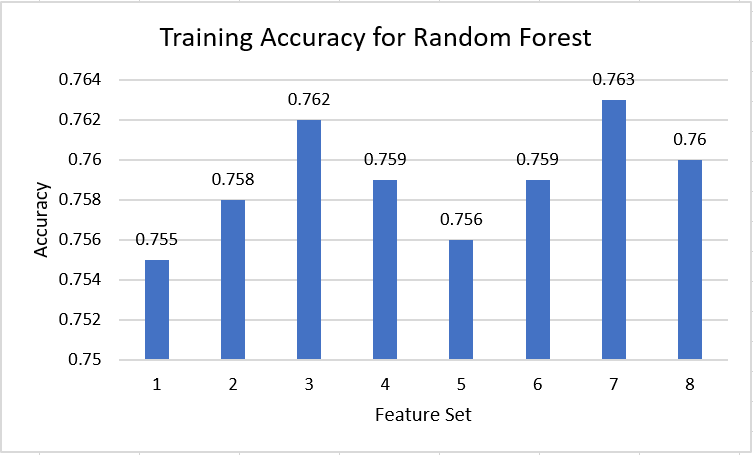
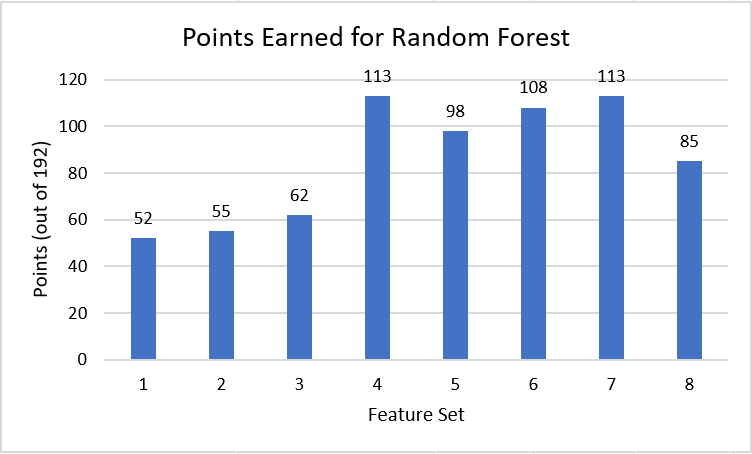
The random forest models all seemed to have a very similar training accuracy (varying less that 1%). However, the points scored by the random forest model varied greatly depending on the feature set that was used. There was a general trend where, as we increased the number of features, the points scored increased. We believe this because, as we increase the number of features, the decision trees the random forest model uses become much more different. This means that while the random forest model for small feature sets is forced to rely on fairly similar decision trees, the model is able to use many very different trees when analysing the larger feature sets. The decrease in similarity between decision trees allows the model to get more accurate and likely led to the increase in points scored seen as the feature sets became larger.
7.png)
Naive Bayes
Naive Bayes is a generative model working under the assumption that features are independent and classifies the data regardless of correlations between features.
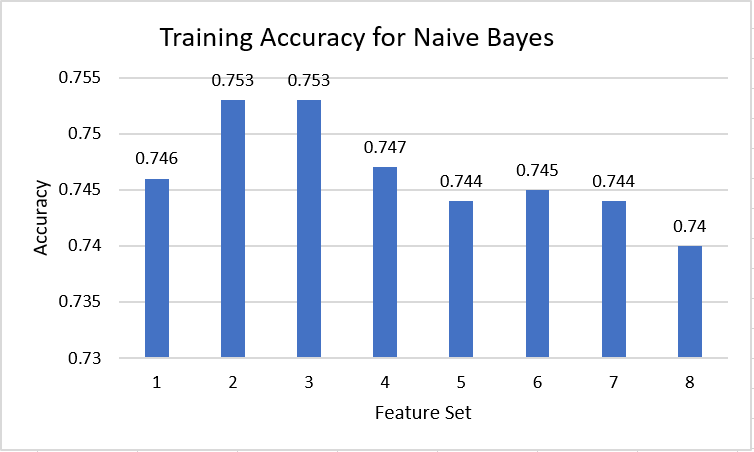
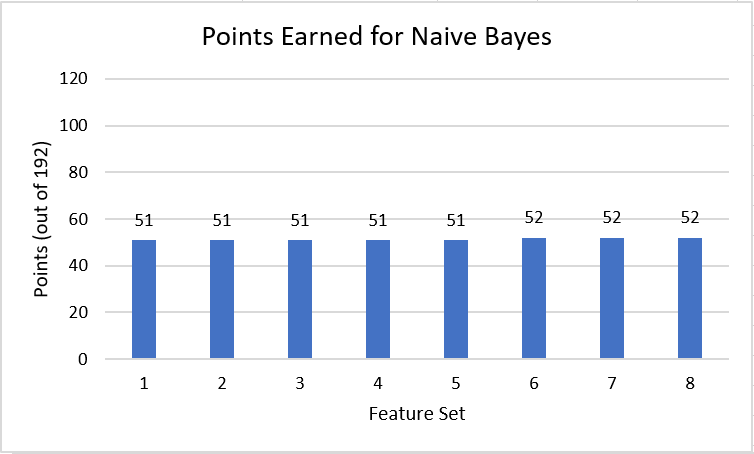
Even though Naive Bayes had different accuracies for all the feature sets, the points was almost all the same. Also, the predictions were extremely confident in each matchup but got many of them wrong. Due to this, there didn't seem to be a relationship between the accuracy and the points. This could be because of the extreme confidence in each prediction. Games that might be closer to a 50% chance might end up being predicted completely wrong by this technique.
8.png)
Neural Networks
Neural Networks uses multiple layers of different weighted nodes that are propogated through by the given features to produce an output.
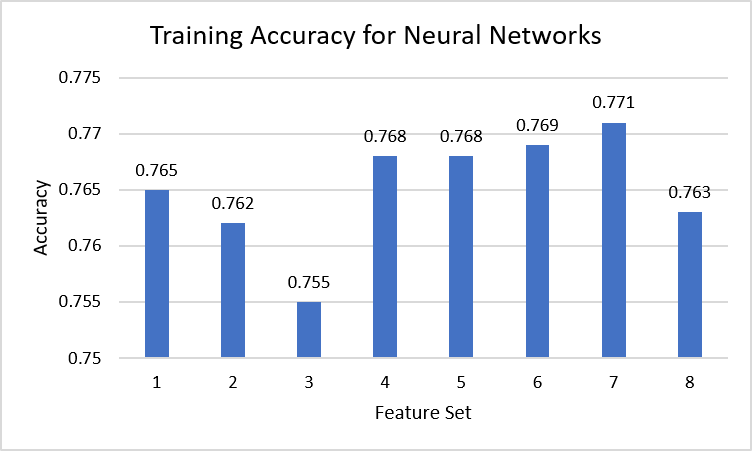
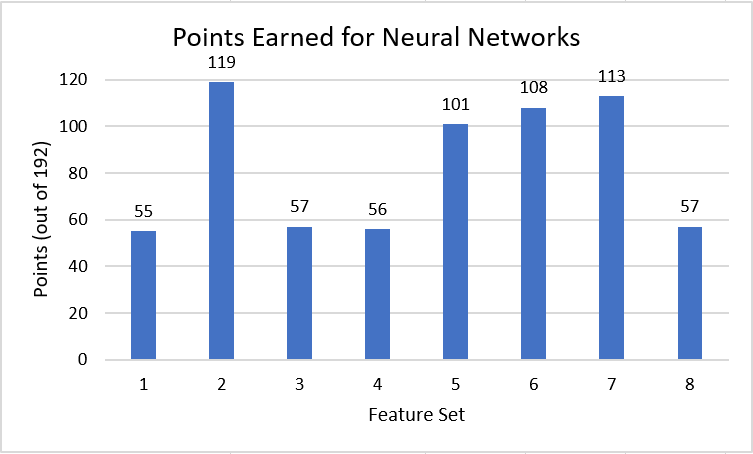
The training accuracies for our Neural Network models were all fairly consistent and close to each other, with all of them falling between 0.75 and 0.78. This range is similar to the training accuracies of the previously mentioned models as well. However, when scoring the brackets produced by the model, different feature sets resulted in different performance levels. For example, sets 1, 3, 4, and 8 were around 55 - 57, which is an average score in march madness tournaments. Sets 2, 5, 6, and 7, however, all predicted with scores above 100, which are significantly higher. When comparing these feature sets, they all contain assists and some form of field goal metric, indicating that these features might work well with the neural network models. Though set 8 also contained these metrics, it also contained most of the available data, which could result in overfitting due to redundant features.
2.png)
Extreme Gradient Boosting (XGBoost)
XGBoost is an ensemble learning method similar to random forests in that it uses decision trees but uses gradient boosting. Gradient boosting sequentially adds trained predictors and assigns them weights and updates the model it is creating using gradient descent. It helps to minimize both bias and variance by using a multitude of decision trees and has historically been considered one of the best models to use when using machine learning to generate predictions. This is due to XGBoost's build-in cross validation and it's use of both LASSO and Ridge regression to prevent overfitting.
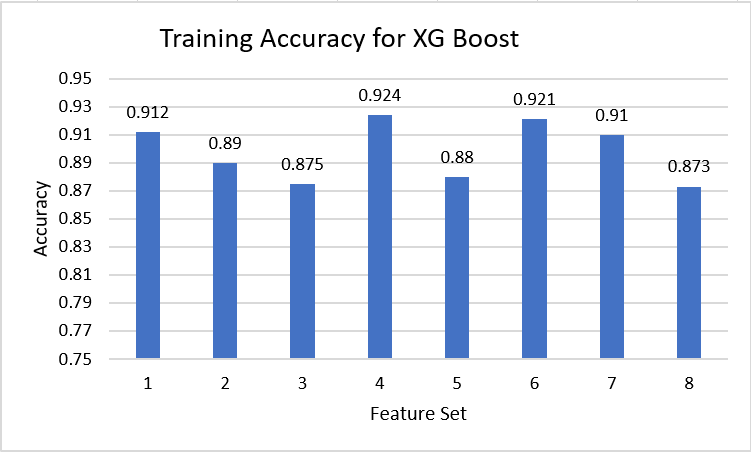
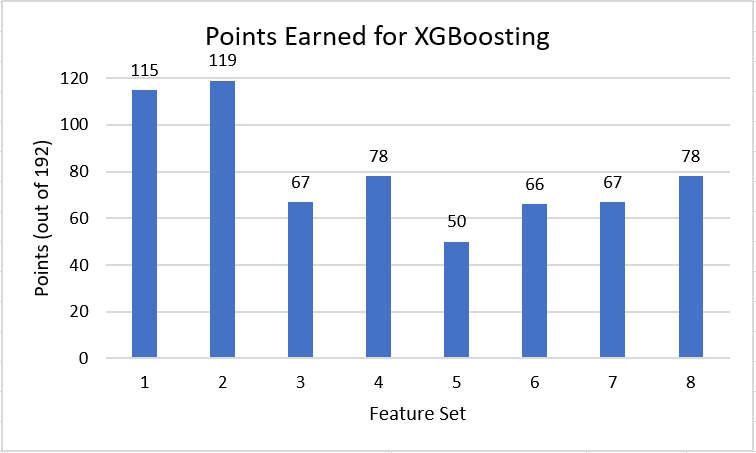
While our XGBoosting models were all able to perform very well in the training, they tended to perform towards the middle of the pack when generating a bracket for the 2019 March Madness competition. We believe this might be due to the fact that we train and test our model based on a mix of data from 1985 to 2019 (not including the 2019 March Madness competition). However, the way basketball has play was evolved over time. For example, the NCAA did not universally adopt the 3 point line until 1986 while 3 pointers are now considered one of the best and most important shots in basketball. So while our model did a very good job of predicting the test data, it was unable to account for the ways basketball has evolved when making it's predictions for the 2019 March Madness competition.
2.png)
Pick Most Confident (Our own ensemble Method)
We wrote a script that would compare bracket predictions from our logistic regression, random forest, xgboosting, and neural networks models. The script would compare the predictions in the models and choose the prediction that had higher certainty, meaning the difference between winning rate of the two teams. The reason behind such decision was that the these models had similar accuracy so we tested if combining the models would improve our accuracy. We did this based on the idea that the more extreme the models prediction (closer to 1 or 0) the more likely it was that that model had picked up on something that gave it a clear indication of who would win. Whereas a model that predicted the probabilities closer to 0.5 was likely unable to see a clear distinction between the two competing teams's performance. The log loss of the model did not change much but the brackets had their accuracy improved by an average of 2% when our pick most confident model was used.
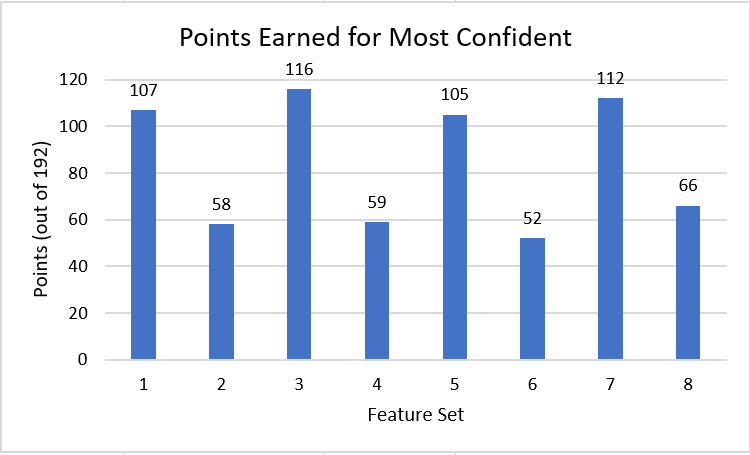
|
3.png)
|
Seeding
Upsets in basketball occur when a higher seeded team loses to a much worse team. Of the 63 games played over the course of each tournament since 1985, there has been on average 12 upsets per tournament. Due to this, we created a higher threshold for lower seeded teams to win; teams that are lower seeded need to have higher than a 50% chance to win in order to move on in the bracket.
Our implementation of seeding has been proven to be quite useful. Given a equal probability distribution (which scored 12 points for its prediction), the seeding implementation predicted a bracket that scored 76. That's roughly a 500% improvement! Our 5 highest scoring brackets all used seeding and there was a 5.4% increase in the average points of the brackets going from unseeded to seeded.
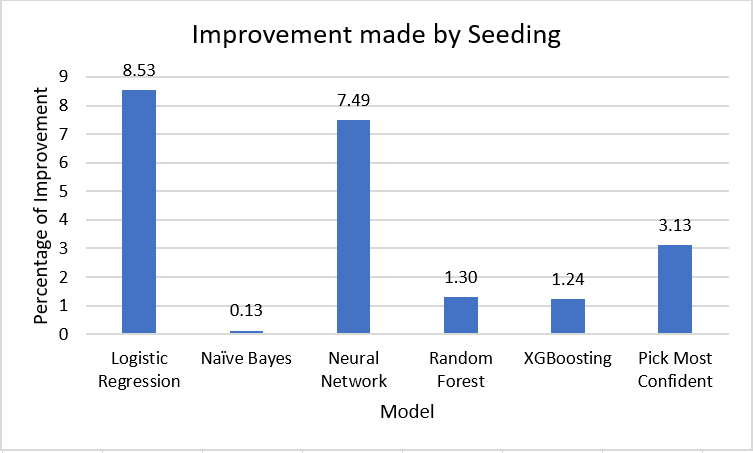
Outside of the ensemble methods, we also noticed a trend that the degree to the improvement in accuracy made by the seeding is affected by the initial accuracy of the model. This is most likely a result of our algorithm making a decision based on the probabilities the model give, which means if the model gives inaccurate probabilities, then our seeding implementation will make a worse decision.
Results
Overall Results
We evaluated each model using the log-loss for the 2018-2019 March Madness tournament as well as how many points the bracket would generate in the NCAA competition. Logistic Regression, along with Neural Networks, performed the best out of the first four techniques and usually had a very close accuracy with Neural Networks. This is most likely the case because of the Neural Network's own logistic regression it uses to calculate the weights. Out of all the feature sets, Naive Bayes consistently performed the worst and had the worst accuracy on the training data. Most notably, the classifier was extremely confident in all of its predicted matchups, even though it predicted many of them incorrectly. Random Forests consistently performed worse than both Neural Networks and Logistic Regression but better than Naive Bayes.
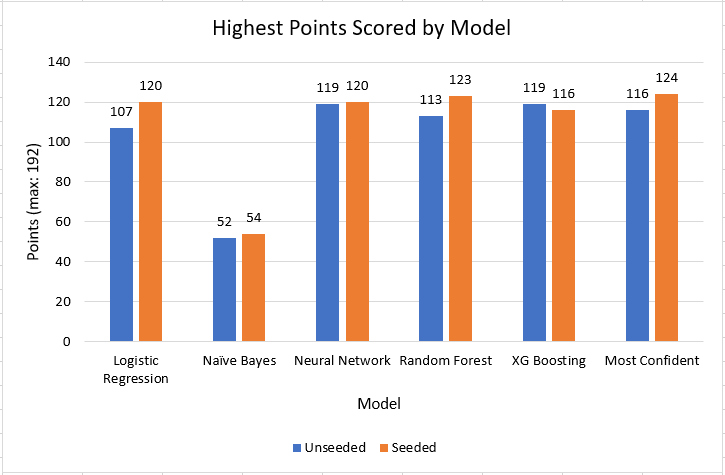
Our 5 best brackets all scored 120 points or above which was far above the 2018 average of 57 points and in addition, 36 of our 96 brackets reached our target and scored over 100 points. Our best bracket, using Pick Most Confident and Seeding for feature set 7, produced 124 points, which could be enough to win a few bets or competitions but is still far from the perfect score of 192. Due to the point system awarding more points in the later rounds, just predicting the winner grants 63 points. While our model does predict the correct winner, it would need to perform even better to predict the final game.
7MCS.png)
Future Steps
Our model's were trained using data that went as far back as 1985. However, the way basketball is played has changed drastically over time. For example, it wasn't until 1986 that the 3 point line was adopted by the NCAA. However, in the modern game, the 3 pointer is one of the most important (and best) shots a player can take. So while old data is definitely valuable, we could probably improve upon our models by having them value data from more recent seasons more than data from older seasons.
Another way we could improve our models would be to try to take experience into account. March Madness is associated with a lot of excitement, close games, and stress as players are forced to deal with environments they have never been in. Teams that have players and coaches who have a lot of experience with March Madness are less likely to be rattled by immense pressure that teams face in March Madness. We believe that by incorporating this factor we can improve the accuracy of our models.
Another way we could improve upon our model is by trying to increase it's ability to predict upsets. We could try to do this by further tinkering with our seeding factor. However, upsets are still fairly hard to predict. Some teams could choke or have important players get injured which would end their tournament run. Using extra features such as player experience or tendency to under perform may help in predicting those upsets.
An additional ML technique we could use is Node Regression. Node Regression slightly modifies Logistic Regression and uses it in the training of Neural Networks.
References
Balakrishnama, Suresh, and Aravind Ganapathiraju. “Linear Discriminant Analysis - A Brief Tutorial.” Institute for Signal and Information Processing 18 (1998): 1-8.
Jaisingh, Karan. “March Madness 2019”. https://github.com/kjaisingh/march-madness-2019
Kumar, Ch Aswani. “Analysis of Unsupervised Dimensionality Reduction Techniques.” Comput. Sci. Inf. Syst. 6.2 (2009): 217-227.
“March Madness Bracket Scoring.” JellyJuke, http://www.jellyjuke.com/march-madness-bracket-scoring.html.
Morde, Vishal. “XGBoost Algorithm: Long May She Reign!” Medium, Towards Data Science, 8 Apr. 2019, https://towardsdatascience.com/https-medium-com-vishalmorde-xgboost-algorithm-long-she-may-rein-edd9f99be63d.
Shlens, Jonathon. “A Tutorial on Principal Component Analysis.” arXiv preprint arXiv:1404.1100 (2014).
Spackman, Kent A. “Combining logistic regression and neural networks to create predictive models”. Proceedings of the annual symposium on computer application in medical care. American Medical Informatics Association, 1992.
“The History of the 3-Pointer.” USA Basketball - The History of the 3-Pointer, https://www.usab.com/youth/news/2011/06/the-history-of-the-3-pointer.aspx.